After understanding the ARIMA Model for Time-series Forecasting, we have to move to its output. When we execute the entire code, we will get some outputs that we need to understand for analysis.
After executing the code, we will get 3 types of output. Let us check the output in the following.
1. ARIMA Model Summary:
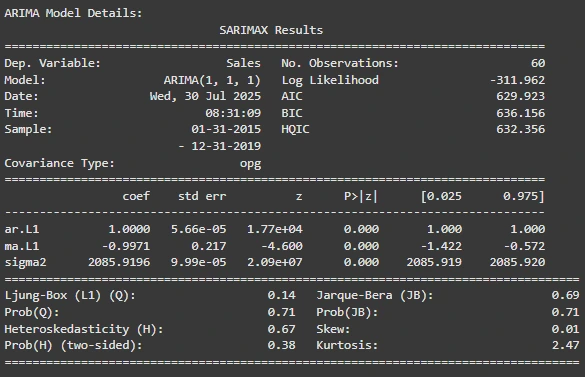
As we have developed the ARIMA Model in Step 4, we will get a summary table. This summary table will tell us the following things. Let us check those in the list below.
- The ARIMA Model is successfully fitted because it has a good score (AIC: 629.92, BIC: 636.15).
- There is no Autocorrelation and Normal Distribution in Residual Diagnostics (Ljung-Box, Jarque-Bera), which shows reliable predictions.
- The Stability of the model is confirmed by the Constant Variance in residuals (Heteroskedasticity Test)
2. Model Evaluation Of 12 Months:

The ARIMA Model Evaluation that we have done in Step 6 will also be printed on the output. From this output, we can understand the following things.
- The ARIMA Model performance was measured by the MAE (66.66) and RMSE (81.14).
- These error values show that forecasting was quite decent, and it is acceptable.
3. Graphs:
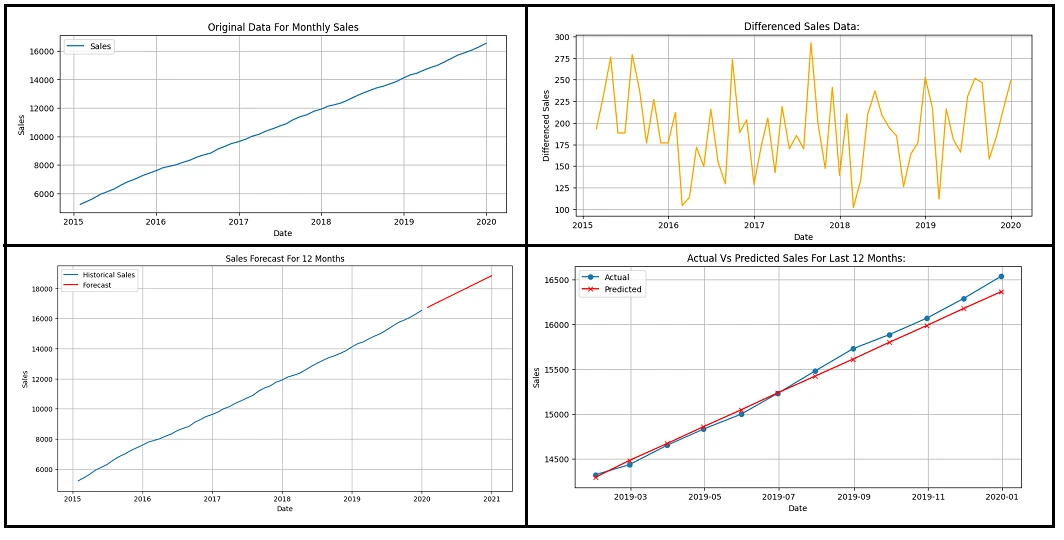
For the remaining steps in the ARIMA Model, we will get 4 graphs. Let us check those graphs and their details one by one from the following list.
- Original Data for Monthly Sales: This shows a steady upward trend for the actual sales data.
- Differenced Sales Data: The Transformed Sales Data after removing the trend is shown in this graph.
- Sales Forecast for 12 Months: The forecasted sales for the next year are mentioned in this graph.
- Actual Vs Predicted Sales: In this graph, we will compare the actual sales with predicted values.
