
When you first learn Dijkstra’s Algorithm, you may feel it a bit technical, but the core idea is actually very simple, which states to always move to the closest unvisited node.
As someone who has taught this for years, I tell students to think of it like finding the shortest route on Google Maps step by step. If you follow the process carefully, you will never get confused, even in complex graphs.
Let us go through the simple and practical algorithm steps mentioned below.
- Start by assigning a distance value of 0 to the source node and infinity to all other nodes because we don’t know their shortest path yet.
- Create a visited set to keep track of nodes whose shortest distance is already finalized.
- Pick the node with the minimum distance and mark it as visited because now its shortest path is confirmed.
- For each neighbor of this node, calculate the new possible distance.
- If this new distance is smaller than the previously stored value, update it immediately.
- Repeat this process until all nodes are visited or the destination node is reached.
- At the end, the distance array will give you the shortest path from the source to every node.
Dry Run: Working Of Dijkstra’s Algorithm
Over the years, I have seen that students only gain true confidence when they trace Dijkstra’s algorithm step by step on a small graph. This is where the Dry Run concept plays an important role.
When you really want to master Dijkstra’s Algorithm, doing a dry run is not optional; it is essential. Think of this as manually simulating how the algorithm “thinks” while finding the shortest path.
To make you understand the working easily, I have broken it up into some effective steps. Let us check them.
Step 1: Initialization
We begin by selecting a source vertex. In this example, we choose A as the starting node. Since this is our starting point, we assign its distance as 0.
For all other nodes, which are B and C, we assign a distance of infinity because we haven’t discovered any paths to them yet. At this stage, none of the nodes are visited.

So, we maintain a clear separation between visited and unvisited nodes. Right now, all nodes are unvisited, and we are ready to start processing from node A.
Step 2: Visit Current Node And Update The Neighbors
Now, we start with node A because it has the smallest distance (0). We mark A as visited since we are now processing it. Next, we look at all its neighboring nodes, which are B and C.
The key idea here is to check whether we can reach these neighbors with a shorter distance through A. This process is called relaxation. For example, if the edge from A to B has a weight of 2, and A to C has a weight of 5, we update their distances accordingly.

So now, B gets a distance of 2, and C gets a distance of 5. This means we have found better paths to these nodes through A.
Step 3: Choose The Next Closest Node
At this point, we do not randomly pick the next node. Instead, we carefully select the unvisited node with the smallest distance value. Between B and C, node B has the smaller distance (2), so we pick B next.
We mark B as visited and repeat the same process. Now, we look at B’s neighbors and check whether going through B provides a shorter path to any node.
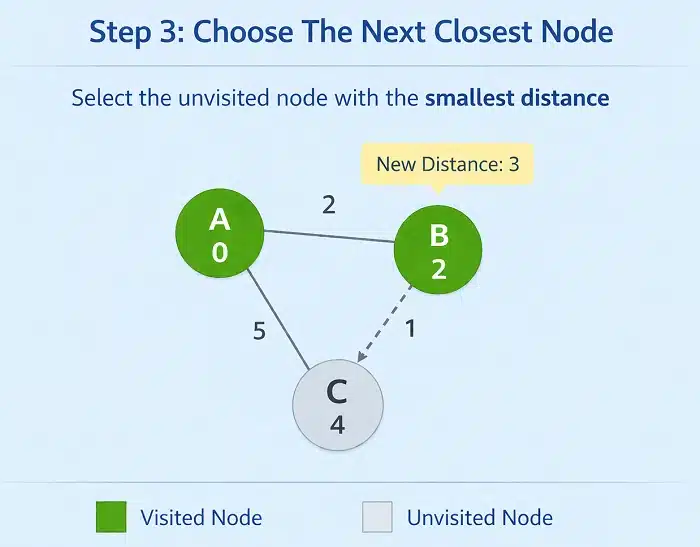
If there is a path from B to C, we calculate the new distance and compare it with the current distance of C. If it is smaller, we update it. This step is crucial because it ensures that we are always moving in the direction of the globally shortest path, not just the locally shortest edge.
Step 4: Process The Remaining Node
Now, only C remains unvisited. Since it is the only node left, we select it and mark it as visited. At this point, all nodes have been processed. There are no more nodes left to explore, and the algorithm terminates.

By now, we have already calculated the shortest distances from the source node A to all other nodes.
Dijkstra’s algorithm relies heavily on selecting the minimum distance node at each step. This process is often implemented using a Priority Queue, which helps efficiently pick the next node with the smallest distance.
Once your concepts are clear, implementation becomes much easier and more intuitive. So, in this section, I will let you know the implementation process of Dijkstra’s algorithm in C++.
For that purpose, I have prepared the following graph. On this graph, we have to apply Dijkstra’s algorithm. We will assume Node A is the starting point and figure out the distance of the other nodes from it using the algorithm.

If you focus on writing clean logic step by step, your C++ implementation will be both efficient and interview-ready.
Steps Of The Program:
- In the above code, we see that we have a graph that has six vertices named from A to F.
- The weights on these are also mentioned. The whole graph is represented in the main() as graph[6][6]
- Now, we pass this graph as an argument to the function dijkstraAlgorithm() that firstly marks all these vertices as unvisited by setting the shortest path tree (Tset) as false.
- Then we take up each vertex one by one and start calculating the distance and updating the distance in the array dist.
- When the whole operation is completed, we print the shortest path from the source of all vertices using the output() function.
Output:
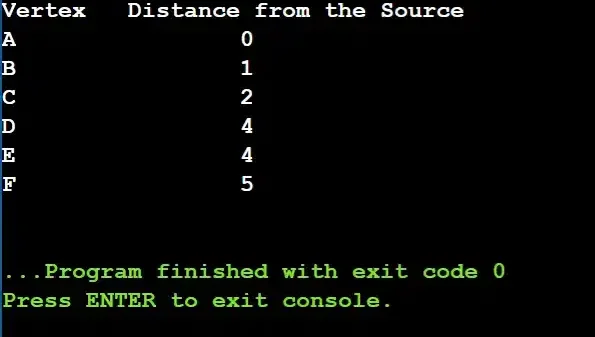
From the above output, we can see all the shortest paths from vertex A to other vertices in the graph. We see that the distance from vertex A is 0, as it is the source vertex. As we move to the other vertices, we can see how adding the weights on the paths gives us the final shortest distance.
What Are The Time And Space Complexities Of C++ Dijkstra’s Algorithm?
As I am mentoring students in DSA for decades, I can tell you that in real-world systems and coding interviews, the Time and Space Complexities become more important than just writing correct code.
Understanding these complexities is important because it tells you whether your solution will scale for large inputs. Let us break down the time and space complexities in a way that you can easily remember.
Time Complexity:
If you are using a priority queue or min-heap, the time complexity is O((V + E) log V)
Here, the V is the number of vertices (nodes), E is the number of edges, and the (log V) factor comes from heap operations like insertion and extraction.
Space Complexity:
The space complexity will be O(V + E). The space complexity includes the Graph storage (adjacency list), Distance array, and Priority queue.
Comparison Table Between Dijkstra, BFS, And Bellman-Ford Algorithms:
Many times, students ask me that they are getting confused between Dijkstra’s Algorithm, Breadth-First Search (BFS), and the Bellman-Ford Algorithm, as they all are used to find paths in a graph.
In such cases, I have to draft a comparison table between them to clarify the confusion. When you compare these algorithms, you start seeing when to use which one; this is where real understanding comes in.
Criteria | Dijkstra Algorithm | BFS Algorithm | Bellman-Ford Algorithm |
Graph Type | Weighted | Unweighted | Weighted |
Negative Weights | No | No | Yes |
Data Structure | Heap | Queue | None |
Time Complexity | Fast | Fast | Slow |
Approach | Greedy | Level | Relaxation |
Cycle Handling | Yes | Yes | Yes |
Use Case | Shortest | Shortest | General |
Why Dijkstra’s Algorithm Fails For Negative Weights?
Since I have been mentoring students for a long time, I have seen this important conceptual question often comes in exams, and many students misunderstand it and lose points. That is why I am clearing it here.
Dijkstra’s Algorithm works perfectly, but under only one condition, which is that all edge weights must be non-negative. If you break this rule, the algorithm can give wrong answers without any warning.
Here is the intuition you should never forget to answer this question:
- Dijkstra’s Algorithm assumes that once a node is visited, its shortest distance is final.
- This assumption completely breaks when negative weights are present.
Suppose you have already finalized a node with a distance of 5. Later, you find another path reaching the same node with distance 3 using a negative edge. But Dijkstra will never reconsider that node, so it keeps the wrong value (5).
If I break down the answer in simpler terms, the following points come. These points you should memorize.
- Negative weights can create shortcuts after a decision is already made.
- Dijkstra does not backtrack, so it misses these better paths.
That is why for graphs with negative weights, we use the Bellman-Ford Algorithm, which safely relaxes edges multiple times.
