
A Correlated Subquery is an important concept in SQL that depends on the outer query to retrieve its values. In a correlated subquery, the inner query references a column from the outer query, which creates a connection between the two queries.
Because of this relationship, the inner query is executed repeatedly for each row processed by the outer query. These subqueries are commonly written using the WHERE clause to compare values between the inner and outer queries.
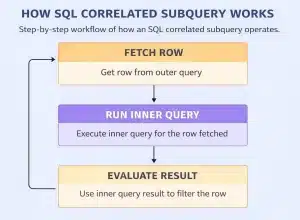
At first glance, correlated subqueries may look similar to normal subqueries. However, the key difference is that a regular subquery usually runs once and returns a result, while a correlated subquery runs multiple times. This repeated execution allows it to perform row-by-row comparisons in a table.
While writing complex SQL queries, it is also important to understand the SQL Order of Operations. This helps you see how the database engine processes different clauses such as SELECT, WHERE, and GROUP BY, which becomes useful when you start working with Correlated Queries.

Step 3: Implement The Correlated Subqueries In The Table
Now, after inserting values into the table, it is time to declare Correlated Subqueries there. For that purpose, you have to use the following query.
Explanation:
The outer query retrieves the Language and Lines columns from the Code table, which is assigned the alias ‘c1’.
The inner query calculates the average number of lines of code for the same programming language using the Code table with the alias ‘c2’.
The condition ‘c2.Language = c1.Language’ creates the correlation between the inner and outer queries.
The outer query then compares the value of Lines in each row with the average returned by the inner query.
Only those rows where the number of lines is greater than the average for that specific language will appear in the final output.
Output:

From the above output, we can see that Python, Java & JavaScript are coming with the Number of Lines. As the Number of Lines is greater than the average number of lines, that is why they appear. So, the Command is executing well.
Explanation:
The outer query retrieves the ID and Developer columns from the Code table, which is assigned the alias ‘c1’.
After the EXISTS operator, the subquery is written inside parentheses.
The inner query checks whether there exists at least one row in the table where the value of Lines is smaller than the Lines value of the current row in the outer query.
If the inner query returns at least one matching row, the EXISTS condition becomes true, and that row from the outer query will appear in the final output.
Output:

From the above output, we can see that all the records are coming except ID Number 4. The ID Number 4 is not coming as the Exists Operator is filtering out the value. So, in this way, you can use other types of SQL Commands as well.
Explanation:
Here, the Outer Query will access the Developer and the Count of Every Programming ID.
The Count of every Programming ID will be termed as the CodeCount in the table.
Now, the Average Line will be selected after the Where Statement in the SQL Command.
At the end, the GROUP BY clause groups the results based on the Developer column.
This can be implemented if the Outer Query Lines are treated before the Inner One.
Output:

From the above output, we can see that only the Bob & SG Developer Names are coming with the Code Count as 1 because they have written the code only in one programming language. So, the SQL Command is working fine.
